
Update (Sept 2017): JAMA has not accepted my [short] response, very critical of this ViewPoint, for publication, saying my response is too vague. It’s quite unfortunate that JAMA does not seem to realize harm caused by such unnecessary alarming articles that are not supported by evidence and rejects a critical reply. I don’t see any reason for that Viewpoint other than to garner citations that tap into opinions not based on evidence.
Update: This has been picked up by a top data science website kdnuggets.com. Also available on medium.com
The Journal of American Medical Association (JAMA) published a viewpoint titled “Unintended Consequences of Machine Learning in Medicine” [Cabitza2017JAMA]. The title is eye-catching, and it is an interesting read touching upon several important points of concern to those working at the cross roads of machine-learning (ML) and decision support systems (DSS). This viewpoint is timely, arriving at a time when others are also expressing concern about inflated expectations of machine learning and its fundamental limitations [Chen2017NEJM]. However, several points put forth as alarming in this piece are in my opinion unsupported. In this quick take, I hope to convince you that the reports of unintended consequences specifically due to ML have been greatly exaggerated.
TL;DR:
Q: Have there been unintended consequences due to ML-DSS in the past? A. Yes.
Q: Were they all due to limitations specific to ML and ML models? A. No.
Q: Where do the troubles arise from? A. Failures in design and validation of DSS.
Q: So what’s the eye-catching title about? A. An unnecessary alarm.
Q: But, does it raise any relevant issues? A. Yes, but it does not deliver on them.
Q: Do I need to read the original piece? A. Yes. This discussion is important.
For the latest and greatest on machine learning in medicine, Follow @raamana_
Comments
The viewpoint is timely and raises several points of concern, ranging from uncertainty in medical data, difficulties in integrating contextual information and possible negative consequences. Although I agree with the viewpoint that these are important issues to be resolved, I do not share their implication (intended or not) that use of ML in medicine is causing it. Some of the keywords used in the viewpoint like overreliance, deskilling and blackbox models are over-generalizing the scope of the limitations of ML models, whether they intended it or not. To my understanding of the Viewpoint, the raised concerns are mostly due to clinical workflow management and failures therein, not due to the ML part per se, which needs to be stressed is only one component of the clinical DSS [Pusic2004BCMJ, see below].

Moreover, the viewpoint completely skipped discussing the effectiveness and strengths of ML-DSS to put their limitations in perspective. Did you know that the annual cost of human and medical errors in healthcare is over $17 billions and over 250,000 American deaths [Donaldson2000NAP,Andel2012JHCF]?
I suggest you to read the original viewpoint [Cabitza2017JAMA] and read my response below to get a better perspective. I do not agree with some of the points viewpoint makes, mostly because they are either exaggerated, not sufficiently backed up or unnecessarily laying the blame on ML. I quote few statements from the Viewpoint below (organized by sections in their piece; emphases mine) and offer a point-by-point rebuttal in the indented bullet points:
Deskilling
- Viewpoint defines deskilling to be the following: “the reduction of the level of skill required to complete a task when some or all components of the task are partly automated, and which may cause serious disruptions of performance or inefficiencies whenever technology fails or breaks down”
- The deskilling point being made is similar to the general decline in our ability to multiply numbers in our head or by hand, as calculators and computers have become commonplace. Implying that we would lose the ability to multiply numbers, with “overreliance” on calculators and computers, is unnecessarily alarming. We may be slower to multiply nowadays compared to pre-calculator era, or have forgotten few speeding tricks, but I doubt we will totally forget how to multiply numbers. Using cars or motor vehicles as an example, even though automated transport has become commonplace, we never lost the ability to walk or run.
- The study cited [Hoff2011HCMR] to support this point was based on interviews with 78 U.S. primary care physicians. A survey! Based on views and experiences of primary care physicians, not objective measurements of effectiveness in a large-scale and formal study. Recent surveys and polls have brought us to the brink of a nuclear war now!
- And the two things they studied in [Hoff2011HCMR] were the use of electronic medical records and electronic clinical guidelines. They were not even based on ML.
- The supporting study concludes “Primary care physicians perceive and experience deskilling as a tangible outcome of using particular health care innovations. However, such deskilling is, in part, a function of physicians’ own actions as well as extant pressures in the surrounding work context.” Perhaps I am missing something, but this does not imply ML or DSS to be the cause of deskilling.
- At the risk of exaggerating it, this deskilling argument sounds to me like some physicians are worried that the “robots” are going to steal their jobs!
- Another example provided to support the deskilling point is: “For example, in a study of 50 mammogram readers, there was a 14% decrease in diagnostic sensitivity when more discriminating readers were presented with challenging images marked by computer-aided detection”
- This is a selective presentation of the results in the cited study [Hoff2011HCMR]. The study also notes “We found a positive association between computer prompts and improved sensitivity of the less discriminating readers for comparatively easy cases, mostly screen-detected cancers. This is the intended effect of correct computer prompts.“. This must be noted, however small the increase may have been. Check the bottom of the post for more details.
Uncertainty in Medical Data
- In trying to show the ML-DSS are negatively affected by observer variability as well inherent uncertainties in medical data, the Viewpoint says: “interobserver variability in the identification and enumeration of fluorescently stained circulating tumor cells was observed to undermine the performance of ML-DSS supporting this classification task”
- The cited study [Svensson2015JIR] to support this statement clearly notes “The random forest classifier turned out to be resilient to uncertainty in the training data while the support vector machine’s performance is highly dependent on the amount of uncertainty in the training data“. This does not support the above statement, and does not imply all ML models (and hence ML-DSS) are seriously affected by uncertainties in input data.
- I agree with the authors on existence of bias, uncertainties and variability in medical data in various forms and at different stages, and these are important factors to be considered. With the emergence of wearable tech and patient monitoring leading to unobtrusive collection of larger amount of higher quality patient data, I think the future of healthcare is looking bright [Hiremath2014Mobihealth].
Importance of Context
In trying to show how ML-DSS made some mistakes in the past having not used some explicit rules, the Viewpoint makes the following statements:
- “However, machine learning models do not apply explicit rules to the data they are provided, but rather identify subtle patterns within those data.”
- While most ML models have originally been designed to learn existing patterns in data, they can certainly assist in automatically learning the rules [Kavsek2006AAI]. Moreover, Learning patterns in data and applying explicit rules are not mutually exclusive tasks in ML. And, it is possible to encode explicit knowledge-based rules into ML models such as decision trees.
- If ML models were incompletely trained (no providing enough sample for the known conditions, nor providing enough variety of conditions to reflect the real world scenarios), or insufficiently validated (incorporating known and validated truths e.g. asthma is not a protective factor for pneumonia as was noted in another example), algorithms are not to blamed for recommending what they were trained on (patients with asthma exhibited lower risk for pneumonia, as was observed in that particular dataset they were trained on).
- “this contextual information could not be included in the ML-DSS”
- This is simply wrong. At the risk of making a broad statement, I can say almost all types of information could be included in an ML model. If you can write it down or say it out loud, that information can be digitally represented and incorporated into an ML model. Whether a particular ML-DSS included context info and why is another discussion, and not incorporating context info into a ML-DSS is not the fault of ML models.
Conclusions
- Viewpoint concludes: “Use of ML-DSS could create problems in contemporary medicine and lead to misuse.”
-
- This is hilarious and such a lazy argument. This sounds like “use of cars could create problems in modern transport and lead to misuse”. Did people misuse cars to do bad things? Sure. Did that prevent motor vehicles from revolutionizing human mobility? No. We are almost at the entry door for self-driving cars, thanks to ML and AI, to try reduce human stress and accidents!
-


Where are the weaknesses in ML-DSS then?
For a general overview of challenges in designing a clinical DSS, refer to [Sittig2008JBI,Bright2012AIM]. A paper Viewpoint cites to support the point on unintended consequences is titled “Some unintended consequences of information technology in health care” [Ash2004JAMIA], which notes that “many of these errors are the result of highly specific failures in patient care information systems (PCIS) design and/or implementation.” And that’s exactly where the blame should lie. The supporting paper goes on to say: “The errors fall into two main categories: those in the process of entering and retrieving information, and those in the communication and coordination process that the PCIS is supposed to support. The authors believe that with a heightened awareness of these issues, informaticians can educate, design systems, implement, and conduct research in such a way that they might be able to avoid the unintended consequences of these subtle silent errors“. These issues identified are nothing to do with ML part per se, but are actually to do with data entry, access and communication! Hence, it is unfair to blame it all on machine learning, as the current title implies.
How would you do it?
Based on the main point the viewpoint are trying to make (which to my reading of it is garbage in garbage out), a better title for this piece could be one of the following:
- “Contextual and Clinical information must be part of the design, training and validation of a machine learning-based decision support system”.
- “Insufficient validation of the clinical decision support systems could have unintended consequences”
- or if the authors really wish to highlight the unintended part, they could go for “unintended consequences due to insufficient validation of decision support systems”
Given the broad nature of issues discussed, and the vast reach of JAMA publications (over 50K views in few days with an altmetric over 570), it is important we do not exaggerate the concerns beyond what can be supported with current evidence. With great reach, comes great responsibility.
Again, the issues raised by the viewpoint are important and we must discuss, evaluate and resolve them. We could certainly use more validation of ML-DSS, but exaggerated concerns and attributing the past failures specifically to ML are not well supported. I understand the author’s limitations in writing a JAMA Viewpoint (very short: 1200 words, few references etc). Hence, I recommend them to publish a longer piece (various options available on the internet) and build a better case. I’ll look forward to reading it and learn more.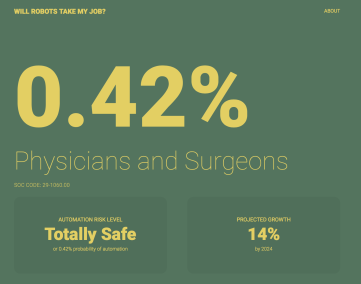
As for whether robots taking physicians jobs in the near future? Seems unlikely, with chances < 0.5%.
Conflict of interest: None.
Financial Disclosures: None.
Physician experience: None
Machine learning experience: Lot.
For the latest and greatest on machine learning in medicine, Follow @raamana_
Disclaimer
Opinions expressed here are my own. They do not reflect the opinions or policy of any of my current, former or future employers or friends! Moreover, these comments are intended to continue the discussion on important issues, and are not intended to be in any way personal, or attack the credibility of any person or organization.
More details
- The mammogram study [Svensson2015JIR] notes the following in their abstract: “Use of computer-aided detection (CAD) was associated with a 0.016 increase in sensitivity (95% confidence interval [CI], 0.003–0.028) for the 44 least discriminating radiologists for 45 relatively easy, mostly CAD-detected cancers. However, for the 6 most discriminating radiologists, with CAD, sensitivity decreased by 0.145 (95% CI, 0.034–0.257) for the 15 relatively difficult cancers.”
- While it is certainly important to understand the causes for decrease in sensitivity for the most discriminating readers with the assistance of CAD (as it is larger than that of the increase in least discriminating readers), it is important to bear in mind that reader sensitivity is only one of multitude of factors to be considered in evaluating the effectiveness of a ML-DSS [Pusic20014BCMJ]. The authors themselves recommend this at the end: “The quality of any ML-DSS and subsequent regulatory decisions about its adoption should not be grounded only in performance metrics, but rather should be subject to proof of clinically important improvements in relevant outcomes compared with usual care, along with the satisfaction of patients and physicians.” Hence, the alarm about the use of ML-DSS leading to deskilling is weak at best, unless we see many large studies demonstrating this in a variety of DSS workflows.
References
- Andel2012JHCF: Andel, C., Davidow, S. L., Hollander, M., & Moreno, D. A. (2012). The economics of health care quality and medical errors. Journal of health care finance, 39(1), 39.
- Ash2004JAMIA: Ash, J. S., Berg, M., & Coiera, E. (2004). Some unintended consequences of information technology in health care: the nature of patient care information system-related errors. Journal of the American Medical Informatics Association, 11(2), 104-112.
- Bright2012AIM: Bright, T. J., Wong, A., Dhurjati, R., Bristow, E., Bastian, L., Coeytaux, R. R., … & Wing, L. (2012). Effect of clinical decision-support systemsa systematic review. Annals of internal medicine, 157(1), 29-43.
- Cabitza2017JAMA: Cabitza F, Rasoini R, Gensini GF. Unintended Consequences of Machine Learning in Medicine. JAMA. 2017;318(6):517–518. doi:10.1001/jama.2017.7797
- Chen2017NEJM: Chen, J. H., & Asch, S. M. (2017). Machine Learning and Prediction in Medicine-Beyond the Peak of Inflated Expectations. The New England journal of medicine, 376(26), 2507.
- Donaldson2000NAP: Donaldson, M. S., Corrigan, J. M., & Kohn, L. T. (Eds.). (2000). To err is human: building a safer health system (Vol. 6). National Academies Press.
- Hiremath2014Mobihealth: Hiremath, S., Yang, G., & Mankodiya, K. (2014, November). Wearable Internet of Things: Concept, architectural components and promises for person-centered healthcare. In Wireless Mobile Communication and Healthcare (Mobihealth), 2014 EAI 4th International Conference on (pp. 304-307). IEEE.
- Hoff2011HCMR: Hoff T. Deskilling and adaptation among primary care physicians using two work innovations. Health Care Manage Rev. 2011;36(4):338-348.
- Kavsek2006AAI: Kavšek, B., & Lavrač, N. (2006). APRIORI-SD: Adapting association rule learning to subgroup discovery. Applied Artificial Intelligence, 20(7), 543-583.
- Povyakalo2013MDM: Povyakalo AA, Alberdi E, Strigini L, Ayton P. How to discriminate between computer-aided and computer-hindered decisions. Med Decis Making. 2013;33(1):98-107.
- Pusic20014BCMJ: Martin Pusic, MD, Dr J. Mark Ansermino, FFA, MMed, MSc, FRCPC. Clinical decision support systems. BCMJ, Vol. 46, No. 5, June, 2004, page(s) 236-239.
- Sittig2008JBI: Sittig, D. F., Wright, A., Osheroff, J. A., Middleton, B., Teich, J. M., Ash, J. S., … & Bates, D. W. (2008). Grand challenges in clinical decision support. Journal of biomedical informatics, 41(2), 387-392.
- Svensson2015JIR: Svensson CM, Hübler R, Figge MT. Automated classification of circulating tumor cells and the impact of interobsever variability on classifier training and performance. J Immunol Res. 2015;2015:573165.
Update: This post has been updated to change the style of citation from numeric to author-year-journal format for improve accuracy and maintenance.

Pingback: Robots aren’t taking doctors’ jobs and it’s okay to be worried they might – claireduvallet
Thank you Pradeep for your long and insightful review. We wrote that Viewpoint because we believe that the consequences of ML technology should matter for everyone who wants to take the role of any innovative technology in medicine seriously: medicine is a delicate field of human knowledge and action where human suffering, fears and hopes are at stake. This fact, that differentiates medicine with respect to almost any other human domain, cannot be understated. For this reason, we are happy that our Viewpoint has raised a rich debate, since this was our ultimate and probable noblest goal: raising awareness. Thus, although the general reception of our Viewpoint was largely positive (and way above our expectations, as altmetric shows – https://jamanetwork.altmetric.com/details/22226466), we are also grateful to the criticisms we received, among which this review, as these latter ones help us understand what the critical points are that is more difficult to explain and let pass to either the public or to the ML experts, who maybe are not so well-versed on how MDs actually work.
Let’s start from where the review ends (” I understand the author’s limitations in writing a JAMA Viewpoint”) as this sheds a more honest light of its main objection (“alarming in this piece [is] in my opinion unsupported”).
Yes, it was a Viewpoint. A Viewpoint is a short piece as the reviewer acknowledges: our initial contribution was fourfold longer and had to be adapted to this format, which must encompass only 8 (eight) references. I would have been surprised if with such a necessary shortening no line of argumentation would seem too concise to the careful readers, as Pradeep certainly is.
Moreover, we find it questionable to assert that a Viewpoint needs to provide strong support for all of its claims: it’s an opinion paper, ie its value stands in its capability to convincingly advocate new courses of research and to chart some of them. A Viewpoint does not have to provide answers (that is the main aim of a research paper instead), but rather to frame a problem correctly (so that apt research questions can be addressed in research papers to come). I hope no one believes that in the current literature both pros and cons of ML-DSS have already been discussed equally and are equally covered (if someone thinks so I’d be grateful if s/he could give me some references to high-impacted contributions – no, blogs an news articles don’t count- that are critical against the ML systems in medicine. We could find just a couple of these articles.). Conversely, we believe that the current literature is strongly unbalanced towards the positive side and that papers “discussing the effectiveness and strengths of ML-DSS” (BTW, what are these? Increased accuracy on real-world data? Reduced costs? please take the real evidence in) are overwhelmingly more frequent than the negative ones. Thus we are convinced that the hype “knob” on the potential use of these systems has already been turned up full blast to add yet another contribution that “put[s the ML-DSS] limitations in perspective”. In such a short contribution as a Viewpoint is to spend any word in favor of ML would be redundant and wasted, a mere rhetorical means we simply could not afford. Where I had more room to express my ideas (e.g., https://healthmanagement.org/c/it/post/pros-and-cons-of-buying-an-oracular-ai-system-for-daily-decision-making-in-a-hospital-setting) I summarized these advantages, as I obviously am aware of their potential as well. For this main reason, our contribution rather aimed to invite all of the stakeholders (especially policy makers, decision makers and… ML developers) to reflect on the fact that medical settings are complex (socio-technical) systems and that some negative and obviously unintended consequences of the wide use of these systems can occur (and by the Murphy’s Law, if troubles can occur, they eventually will). Thus, the claim that we pinpoint ML as the only cause of troubles is undeserved: however, we do not concur that “the raised concerns are mostly due to clinical workflow management and failures therein”. Rather the concerns we shed light on are mainly due to the data-oriented culture that ML-DSSs entail. At this point, we cannot keep under the wraps the fact that the surreptitious justification of ML-DSS raised in the review (“Did you know that the annual cost of human and medical errors in healthcare is over $17 billions and over 250,000 American deaths [12,13]”) looks just an eye-catching and rhetorical question to an insider. More than this, it is just an ill-grounded claim. First, there is no evidence ML-DSS would decrease medical errors. If such an evidence had been taken, we would have never written that Viewpoint. Second, the whole topic is controversial (what is a medical error? what does it mean an error is preventable? and so on and so forth). Interested people could want to consider this important topic by also consulting these two very knowledgeable sources:
https://www.statnews.com/2016/05/09/medical-errors-deaths-bmj/
https://www.nytimes.com/2016/08/16/upshot/death-by-medical-error-adding-context- to-some-scary-numbers.html
Addressed the main objection above, in what follows we give shorter answers for the other points that we believe flawed in the review, at least those that stroke our imagination most.
Deskilling
I do not understand the exclamation mark. Yes, it was a survey. Surveys are one of the main tools of qualitative research. They should not be confused with pools. We do take those tools seriously, and used them extensively (cf. http://www.inderscienceonline.com/doi/abs/10.1504/IJWBC.2017.082728). We are not the only ones considering qualitative research important (http://www.bmj.com/content/352/bmj.i563).
That said, we mentioned the study [5] to introduce the problem of deskilling as a consequence of overrelying on technology, not on ML-DSS. Deskilling based on ML-DSS is difficult to assess as, to our knowledge, there have not been ML-DSS used on a daily practice in any real setting for long enough to detect this effect. This is a potential unintended consequence that we must be aware of, as we believe it is one of the most serious ones and impactful.
It would be not an exaggeration, but just a misunderstanding. The examples of the calculators and cars are easily debunked. We can concur that digital calculators could have deskilled most of us in doing math by hand,
but, as a whole, this technology allows us to accomplish much more complicated calculations and more quickly. I add an example: maybe we have become less good in remembering sequences of figures like the phone numbers of our acquaintances, but we have also acquired new skills to retrieve any sort of information through a simple Web search. These and similar examples are an oversimplifications that just miss the point about what the job of a doctor (or nurse) really is. It is not a matter of some cognitive functions being substituted or augmented by automation: it’s a matter of changing how medical knowledge is built, learnt, and put to use. We are not delegating just mere calculations or physical functions to the machines but, in the case of ML-DSS (at least in the minds of some strong believer in the AI potential in medicine) the interpretation of complex phenomena (including claims of scientific evidence reported in the impacted literature), decision making, and treatment planning. The cars example, which doesn’t even remotely fit the complexity of real-life healthcare, can be refuted with some irony, by mentioning this very recent stance by the Insurance Institute for Highway Safety (https://www.wired.com/story/self-driving-cars-insurance-ambiguity/)
Ironically, we also could say that selective presentation looms over this point of the review. The increase (in the Povyakalo et al study, not Hoff’s one) re diagnostic sensitivity was detected in the less expert doctors (ML as support for learning) and was of only 1.6%. The decrease of the diagnostic sensitivity of the more expert doctors instead was of 14%: a ten-fold (1 order of magnitude) difference. Moreover, one could also argue that the impact on the more expert doctors should be considered more important than the impact on in-development residents and young doctors, which are often helped by the more expert ones.
This is a recurring misunderstanding: in our Viewpoint we do not issue alarms. We raise awareness on potential drawbacks of ML-DSS to call for more research on them (that is lacking). What evidence can be brought in to say that this consequence will not occur? Engineers reason about risk in terms of odds and impact. Even if deskilling were improbable, its impact would change medicine as we know it. For this reason, we made the point that we need further research in this direction.
Uncertainty
The uncertainty argument is one of those we care more about (because we thought it would be the most misunderstood one). We wrote a whole new contribution on it on which we’d love some sound feedback: https://arxiv.org/abs/1706.06838 . In saying that no all models are affected by uncertainty there is a potential misunderstanding about what uncertainty in medicine is. It is not noise. It is that one MD can see one thing black and another, equally good, can see it white. And both, to some extent could be right. Mainstream ML just does not consider THIS sort of uncertainty, and some other lines of research that do it should receive more attention and attract more researchers (who wish to be serious with ML in medicine)
We could not disagree more, for a number of quite concrete risks related to the medical consequences of using these large amounts of “high” quality data, like overdiagnosis, overtesting, overtreatment, increase in false positive rate, unnecessary stress for these latter ones and so forth and so on. Addressing this divergence (with references, points, resources) would be out of scope here. However, we can suggest an illuminating article that we’d like to discuss in some other work of ours: Vogt H, Hofmann B, Getz L. The new holism: P4 systems medicine and the medicalization of health and life itself. Medicine, Health Care and Philosophy. 2016 Jun 1;19(2):307-23. (https://www.ncbi.nlm.nih.gov/pubmed/26821201). Are we saying that “the worst is yet to come”? Maybe not. But all depends on the general awareness (of the main stakeholders as well as of the people) of the intrinsic risks of the “quantified self” and “continuous monitoring” philosophy that permeates the wearable tech and the related big data.
Importance of Context
Short rebuttal: almost all types of information can be included in hindsight. Simply not all information can be beforehand.
Longer answer: the mentioned sentence was revised several times, also in direct correspondence with the first author of that important study. We were in two minds between the phrases “could not be” and “was not”. Both are correct. The former one is right in light of what said in the short rebuttal. The latter one is right in light of what simply happened at the clinical settings where the study was conducted. Once again though, the problem is not that “almost all types of information could be included in an ML model”, but that what would be necessarily kept out could act as a confounding variable biasing the ML-DSS recommendations. The problem is serious if the ML-DSS is also a black box, as the most accurate of them end up by being (* neural networks are very good in discriminative detection, less good in giving explanations for their predictions, as widely known).
Conclusions
We are working on them. They will be more empirical studies, as we also are eager to contribute in our own little way to the literature gap that we reported in our Viewpoint. To start, I suggest you to look at these two ones:
Cabitza, F., 2017. Breeding electric zebras in the fields of Medicine. arXiv preprint arXiv:1701.04077 (https://arxiv.org/abs/1701.04077)
Cabitza F, Ciucci D, Rasoini R. A giant with feet of clay: on the validity of the data that feed machine learning in medicine. arXiv preprint arXiv:1706.06838. 2017 Jun 21. (https://arxiv.org/abs/1706.06838). The latter one will soon be discussed in an AIS conference in October and then published on a Springer book chapter. Any feedback on both sources is highly welcome, as implied by our sharing them on the ArXiv platform first.
Let me close this short rebuttal with a word of total and sincere convergence with the review. We also strongly purport that that these themes are important and that we must discuss them at length. Our Viewpoint just aimed to concisely list them and convey their gist. We welcome any voice on that Viewpoint as, indirectly, it is a voice about those problems (or just potential problems) that we care so much about. The lack of RCT on the success of ML-DSS, their general inscrutability, the fact that they just output biased data if feed with biased input, the importance of context over data, their role as potential confounding factor have to be considered seriously, regardless one’s one preferences, attitudes and beliefs: these very factors have also been mentioned in a recent journalistic inquiry on the lot of probably the most famous of the ML-DSS: IBM Watson Health (https://www.statnews.com/2017/09/05/watson-ibm-cancer/). It cannot be a coincidence.
For all these reasons, we are really happy to discuss any point. Any discussion is worthy, as it can be seen as a contribution in making ML experts and programmers increasingly aware of a simple fact: developing machines supporting medical work is way different than developing machines for any other domain (this is just personal opinion, though).
Joke corner
As for the review’s title (a question that asked me at least two Twitters), my 140-character response in this Tweet: https://twitter.com/cabitzaf/status/899573142879961088
As for whether robots taking software developers’ jobs in the near future? Not so unlikely.
https://willrobotstakemyjob.com/15-1133-software-developers-systems-software
Maybe I should write a piece entitled “Are ML developers worried about physicians realizing that they don’t need their models?” 😉
Conflict of interest: None.
Financial Disclosures: None.
Physician experience: Lot (not me, but my JAMA co-authors, who helped me in this rebuttal)
Machine learning experience: Lot (mine, not in developing new models, but in applying mainstream ones in medical practice)
LikeLike
I agree with this blog post’s assessment about machine learning.
LikeLike