
A particularly frustrating confusion exists when referring to the different dataset splits when performing nested CV: whether the split in [the really] outer CV loop is to be called test set or validation set, and whether the “test set” in the inner-CV loop is to be called validation set or test set. There are different “traditions” people follow in different domains and textbooks, be them in biostats+medicine, or the core machine learning or computer vision. As different teachers and speakers adopt one or other without clear coordination, you can see how the confusion arises, esp. in cross-talk between inter-disciplinary researchers that started in different domains and learning from different textbooks/teachers. Some of us argue for whichever tradition we started with, and even if we all stick to one, the terms “validation” and “test” do not truly convey their real purpose! Hence, to help alleviate this confusion and make it easy and intuitive to remember this important CV terminology in an unambiguous manner, I suggest we refer to them as the tuning and reporting sets, as outlined in the following schematic:

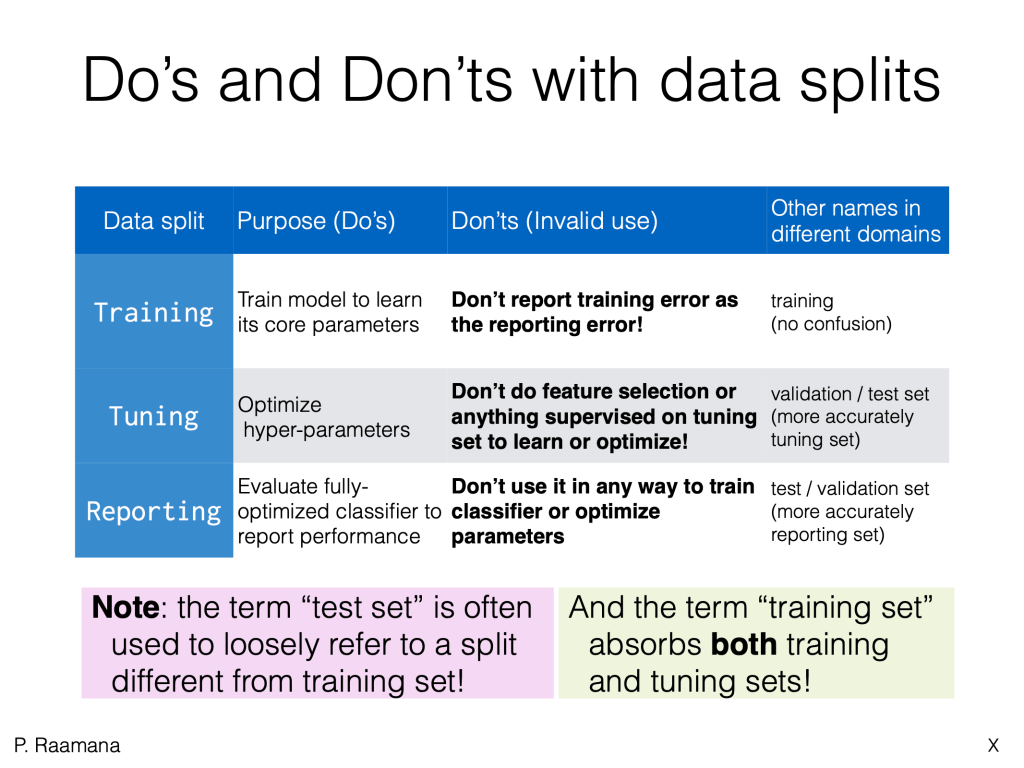
To further clarify their purpose and potential invalid uses, here is another table:
A longer form tutorial is available in the slides below, which were prepared for the machine learning educational course at OHBM 2020. I will be linking to the video soon when it’s available, so stay tuned!
An earlier version of this tutorial with older/confusing terminology is available here.
To improve adoption of best practices, and to produce correct and stable estimates of predictive performance, I developed the neuropredict and confounds python libraries. I invite you to help me improve and contribute to them, in whichever ways you can.
You might also be interested in some of my other open source work.
Stay safe and healthy. Cheers!

Thanks great posst
LikeLiked by 1 person