
TL;DR Summary:
- News: my talk at PyCon Canada 2018 summarizing my thoughts for the broader context of research software development is available here.
- Python and its ecosystem are ideal for neuroinformatics, and we must try to get all the essential and established techniques implemented in pure python
- Community efforts (for testing & validation) must be focused on fully open source software (e.g. those in pure Python with an open source approved license)
- Community efforts for informatics work must be financially supported and formally credited by scientific societies and funding agencies
- One approach could be via official endorsement of software that are fully open source, publicly validated and follow the best practices
- Discussion in this direction could be kickstarted with an INCF special interest group. Sign up here if you are interested.
- A collection of links to useful resources related to migrating from Matlab, building python packages, testing them thoroughly are included at the end
- Share your thoughts and participate.
As I worked on developing and contributing to various neuroinformatics tools, I have learned about a great deal of software development in neuroimaging that happened in the past decades. One thing that is clear, from my own experience as well as from other users, is that using neuroimaging software is anything but easy. By usage, I meant to include all the following: installation, learning the tools, documentation, bug fixes and updates to the latest versions. I am not referring to finishing a previously well-defined task using a software with a manual, but to the entire lifecycle of a research project (typically somewhere between 6 months to 3 years). If you keep a small non-informatics-oriented lab without any IT support in mind as the target user, it’s easier to appreciate this problem. I also learnt how important it is for the software to be easy to install as well as easy to update for users and developers alike to fully adopt it and depend on it for their research. So, what I’m hoping to do in this blog post is to convince neuroscientists that by allocating our precious resources towards developing and refining our ecosystem in Python first and in Python only when possible, we can achieve an easy to use ecosystem, where researchers from all skill levels of neuroinformatics can contribute.
By software, I don’t refer to the rather well-developed AFNI, FSL or Freesurfer, which have large enough user base and support articles and forums, but algorithms and pipelines that requiring a mix of diverse techniques, which are not all implemented in a single ecosystem. Although we use the popular tools for many reasons, we’re more often interested in extending them in interesting and novel ways, and hence requiring access to the source code. Given the aforementioned tools are implemented in C/C++, it presents a big barrier to those without any computer science background and serious programming experience, to learn the toolkit as well as to contribute. The Nipype project offers a great interface to make it easy to stitch together a complex mix of parts from the aforementioned non-python ecosystems. However, it does not remove the dependency on them. You can partially get around with it installing a containerized version, which not only is an additional dependency, but makes it harder to use for a basic user (imagine a psychology undergrad without any training in IT or programming). The super-long and complex docker command lines turn me off and I essentially live in the command line :)..
How can we make it easier going forward, and improve the status quo is the question I would like to discuss today. IMHO the biggest barrier is the precious resources allotted towards neuroinformatics, which include but not limited to:
- limited funding for science and even smaller amounts for informatics,
- limited developer time (expert and novice included),
- community efforts towards testing, documentation and adoption
In addition, some of the barriers I’ve noticed were:
- insufficient training (learning the technologies to be able to contribute)
- insufficient resources (brainstorming design, code review, add documentation)
- insufficient encouragement (by PIs, in academic credit and recognition)
I don’t mean to imply “it’s awful, run away”, I just want to note that there are barriers to entry and the cost of development is high, even though it’s not always quantified and communicated in dollar amount. Although many great efforts are already under way (brainhacks, summer schools and journals dedicated to open source software), we could certainly multiply their value by focusing our efforts as a community. In this context, the desirable characteristics for a neuroinformatics tool would be:
- it must be easily deliverable to the typical user environment i.e.
- requiring minimal additional setup on top of base operating system
- requiring no steep learning curve of learning multiple technologies
- it must be based on technology that lets “everyone” contribute. By everyone, I mean those with minimal programming skills i.e. undergraduate or graduate students just getting introduced to neuroscience and/or programming.
- Think about how awesome it would be to turn many of the university course projects into useful and lasting contributions to the community? Can we utilize their projects to validate the ecosystem better?
- its ecosystem must provide the necessary libraries, covering
- scientific computing i.e. medical image processing, machine learning, statistics and visualizations
- portability i.e. being able to go from batch-processing on a high-performance computing cluster to live dashboards on a browser
- as well as provide broad range of visualization capabilities i.e. from simple bar plots in your IDE to a complex collage of 3D triangulated meshes on a web-browser, which must be flexible and easy enough to be customized.
I am not going to review the pros and cons for python compared to matlab and Javascript in detail here (for more detailed comparisons of matlab vs. python: you can check this, this, this and a slightly biased comparison from Mathworks; and for JavaScript vs. python: check this, this, this and this), but merely mention that python excels at most of the aforementioned categories and the gap in browser-based visualizations (compared to Javascript) is rapidly being closed (plotly’s Dash is an excellent example). In this context, the case for Python to be the programming environment of choice for neuroinformatics is clear and strong:
- Python is full-fledged, supporting the full range of scientific computing e.g. data gathering, manipulation and visualization!
- Python presents less of a barrier for newcomers to learn and join in (python is very similar to pseudocode) and hence encourages contributions to existing software
- Python offers the ability to script something quickly (be it a numerical calculation or full-fledge algorithm), which could easily be grown into a distributable package later on without much effort
- Python is the best programming language to learn machine learning, which is now pervasive in all research domains, academic or otherwise
- And “Python is the second-best language for everything“, which can also be clearly evidenced by its incredible growth (see figure below), as well as typically the most recommended as the best language to learn first.
I think Python is an ideal choice for neuroinformatics and I’d vote for it. Do you?
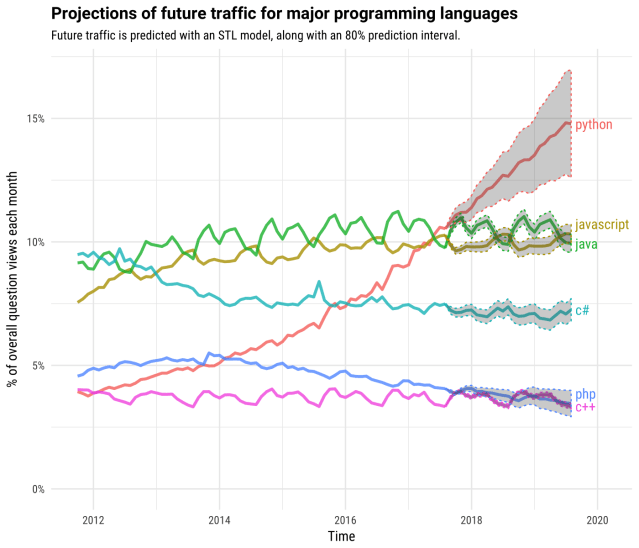
The neuroimaging in python (nipy) community already provides many essential and interesting tools. However, it’s not yet comprehensive enough to cover the full spectrum of neuroscience research and we still need to rely on older C++/C ecosystems. For example, for any non-trivial analyses of functional or diffusion MRI data, we need to rely on AFNI or FSL for one or more basic preprocessing steps (such as correction of head motion, slice timing, or eddy current distortions). Moreover, in my personal opinion, nipy could benefit from better delineation of functionality across some packages, which can help reduce overlap and confusion, as well as effective allocation of community effort towards development, verification and validation (check this post for disambiguation). While some nipy projects are active and thriving, some are effectively out of oxygen. I would like us all to work together towards reducing the wastage of previous efforts.
With those in mind, my suggestions are as follows:
- let’s concentrate our community efforts in
- developing an open source ecosystem in Python, wherein all the established and essential techniques are implemented
- testing, validating and documenting these implementations
- develop programs (funded or voluntary or a mix) incentivizing these efforts
- let’s lobby funding agencies and scientific societies towards structured support for
- publication of validation methodologies
- support and credit for community validation
- official endorsement of tools as a society
Just after the amazing OHBM 2017 meeting in Vancouver, I’ve done an informal survey (twitter thread) on the possibility of getting OHBM to support these efforts financially, and there is clear and strong support (45% voted in favour among those who took it seriously) towards such or similar effort:
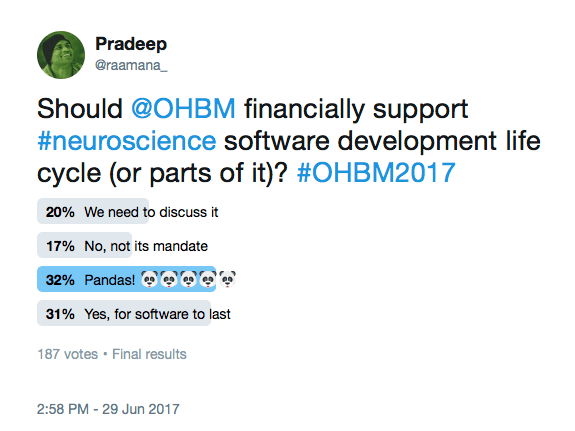
There have been many interesting suggestions, leaning towards open software validation as a scientific society, establishing easy and agnostic validation guidelines, and badges to encourage the adoption of best practices, eventually leading to their endorsement.


Although I got this idea during the OHBM 2017 Town Hall meeting, OHBM certainly doesn’t have to be solely responsible. The International Neuroinformatics Coordinating Facility (INCF) is probably better suited to lead this. However, I hope OHBM is also closely involved to ensure the target user’s perspective is taken into account in various wider community consultations.
How can we focus community efforts?
Some ideas I could think of are:
- A special interest group at INCF focused on software development and validation, which could kickstart and lead the discussions on identifying the gaps to be filled, in development as well as validation
- Finding ways to financially support (anyone from NIH and other funding agencies reading this?) validation efforts e.g. small grants to fund summer students, or a Google Summer of Code project to improve interoperability of an ecosystem
- Incentivizing the adoption of best practices, and contributing to existing open source ecosystems, e.g. with prizes and recognition such as “bug hunters” (like bounty hunters, but for finding and fixing software bugs), “Dr. Docs” (great contributions to documentation), or “master testers” (contributors of detailed and unit/integration tests for essential software). This is similar to the Education in Neuroimaging and Replication awards we already have at OHBM.
- INCF already has funding programs to encourage the development of standards and best practices and it would be awesome to include software validation as a new program, as well as funnel the existing informatics efforts towards a single common open source ecosystem.
What do you think? Let me know your comments.
I will be attending OHBM 2018 in Singapore and Neuroinformatics 2018 in Montreal, hit me up if you are attending them too and I would love to discuss this further.
Follow me on twitter @raamana_ and check out my tools at github.com/raamana.
Useful links
- Software engineering
- Differences between verification and validation
- Credit for academic software development
- Journal of Open Source Software http://joss.theoj.org/about
- Comprehensive list of journals that accept software publications
- Matlab to Python migration guide
- Numpy has an excellent migration guide for matlab users
- Enthought has a white paper and webinar on moving from Matlab to Python
- Tool to automatically convert simple Matlab code to Python is SMOP
- Learn Python
- Turn your Pythons scripts or library into a sharable package
- Testing

Pingback: Why is Python ideal for research software development? – cross invalidation